In part 2 of this series, we showed you how to use Amazon SageMaker Studio notebooks with natural language input to assist with threat hunting. This is done by using SageMaker Studio to automatically generate and run SQL queries on Amazon Athena with Amazon Bedrock and Amazon Security Lake. The Security Lake service team and the Open Cybersecurity Schema Framework (OCSF) community continue to add additional log sources and OCSF mappings to enable Security Lake to provide a consolidated source for customers to conduct security investigation.
Because security logging data sources continually grow, organizations need to provide a mechanism for their security teams to understand and query those data sources. You might have existing investigation and response playbooks that your security teams need to be well-versed in and know when to use. It can take security teams an extended period of time to onboard and understand the available security data sources and playbooks and how to efficiently use them to reduce the mean time to respond.
In this post, we show you how to extend the functionality from the previous post. You will learn how to deploy a security chatbot with a graphical user interface (GUI) and a serverless backend powered by an Amazon Bedrock agent that incorporates existing playbooks to investigate or respond to a security event. The chatbot demonstrates purpose-built Amazon Bedrock agents that help address security concerns depending on the user’s natural language input. The solution has a single GUI that provides a direct interface with the Amazon Bedrock agent to create and invoke SQL queries or provide recommendations for internal incident response playbooks to investigate or respond to possible security events.
Security chatbot sample solution overview
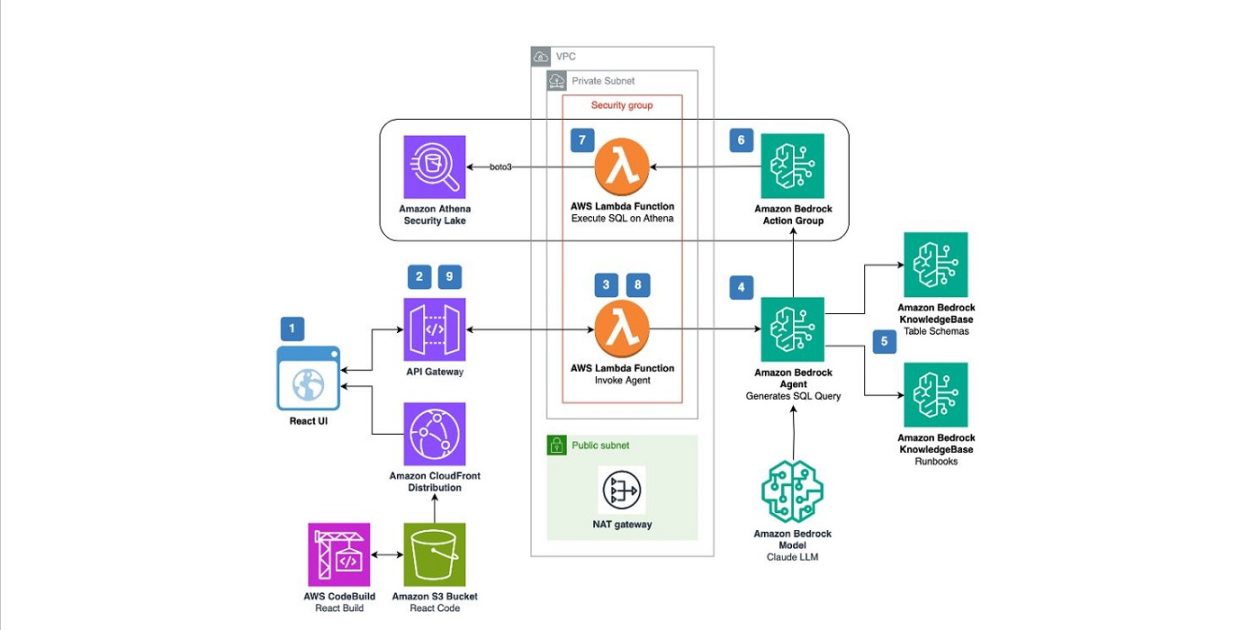
Figure 1: Security chatbot sample solution architecture diagram
Application flow as shown in Figure 1:
User submits a query through the React UI.
Note: The React UI used in this solution doesn’t have authentication built in. It’s recommended that you add authentication capabilities that follow your organization’s security requirements. You can add authentication capabilities by using Amazon Cognito and AWS Amplify UI.
The user’s query is sent to an Amazon API Gateway REST API, which invokes the Invoke Agent AWS Lambda function.
The Lambda function invokes the Amazon Bedrock agent with the user’s query.
The Amazon Bedrock agent (using Anthropic’s Claude 3 Sonnet) processes the query and decides between retrieving information from the playbooks or by querying Security Lake using Amazon Athena.
For playbook knowledge base queries:
The Amazon Bedrock agent queries the playbooks knowledge base and retrieves relevant results.
For Security Lake data queries:
The Amazon Bedrock agent queries the schema knowledge base and retrieves the Security Lake table schemas to create an SQL query.
The Amazon Bedrock agent invokes the SQL query action from the Amazon Bedrock action group, passing the SQL query as a parameter.
The action group invokes the Execute SQL on Athena Lambda function, which executes the query on Athena and returns the results to the Amazon Bedrock agent.
After retrieving results from the knowledge base or action group:
The Amazon Bedrock agent uses the retrieved information to formulate the final response and sends it back to the Invoke Agent Lambda function.
The Lambda function sends the response back to the client using an API Gateway WebSocket API.
API Gateway delivers the response to the React UI using a WebSocket connection to the client.
The agent’s response is displayed to the user in the chat interface.
Prerequisites
Before deploying the sample solution, complete the following prerequisites:
Enable Security Lake in your organization in AWS Organizations and specify a delegated administrator account to manage the Security Lake configuration for all member accounts in your organization. Configure Security Lake with the appropriate log sources: Amazon Virtual Private Cloud (Amazon VPC) Flow Logs, AWS Security Hub, AWS CloudTrail, and Amazon Route53.
Create subscriber query access from the source Security Lake AWS account to the subscriber AWS account.
Accept a resource share request in the subscriber AWS account in AWS Resource Access Manager (AWS RAM).
Create a database link in AWS Lake Formation in the subscriber AWS account and grant access for the Athena tables in the Security Lake AWS account.
Grant Anthropic’s Claude v3 model access for Amazon Bedrock in the AWS subscriber account where you will deploy the solution. If you try to use a model before you enable it in your AWS account, you will get an error message.
With the prerequisites in place, the sample solution architecture provisions the following resources:
Amazon CloudFront with an Amazon Simple Storage Service (Amazon S3) origin.
An Amazon S3 static website for the chatbot UI.
An API Gateway to call a Lambda function.
A Lambda function to invoke the Amazon Bedrock agent.
An Amazon Bedrock agent with a knowledge base.
An Amazon Bedrock agent action group to generate and invoke SQL queries on Athena.
An Amazon Bedrock knowledge base to reference example Athena table schemas in Security Lake. Although the Amazon Bedrock agent can get rows directly from the Athena table, providing example table schemas improves SQL query generation accuracy for table columns in Security Lake.
An Amazon Bedrock knowledge base to reference existing incident response playbooks. By incorporating this knowledge base, the Amazon Bedrock agent can suggest actions for investigation or response based on existing playbooks that have already been approved by your organization.
Cost
Before deploying the sample solution and walking through this post, it’s important to understand the cost of the AWS services being used. The cost will largely depend on the amount of data you interact with in Amazon Bedrock and by querying Security Lake with Athena.
Security Lake costs are determined by the volume of log and event data ingested from AWS services. Security Lake orchestrates other AWS services on your behalf, which incur separate charges. You can find more information on pricing for the respective services: Amazon S3, AWS Glue, Amazon EventBridge, AWS Lambda, Amazon Simple Query Service (Amazon SQS), and Amazon Simple Notification Service (Amazon SNS).
Amazon Bedrock on-demand pricing is based on the selected large language model (LLM) and the number of input and output tokens. A token is comprised of a few characters and refers to the basic unit of text that a model learns to understand the user input and prompts. For more details, see Amazon Bedrock pricing.
The SQL queries generated by Amazon Bedrock are invoked using Athena. Athena cost is based on the amount of data scanned within Security Lake for that query. For more details, see Athena pricing.
Deploy the sample chatbot
You can deploy the sample solution by using AWS Cloud Development Kit (AWS CDK). For instructions and more information on using the AWS CDK, see Get Started with AWS CDK.
Clone the sample-generative-ai-chatbot-for-amazon-security-lake repository.
Navigate to the project’s root folder.
Install the project dependencies.
Build and deploy the app using the following commands:
npm install -g aws-cdk
npm install
cdk synth
Run the following commands in your terminal while signed in to your subscriber AWS account. Replace with your account number and replace with the AWS Region that you want the solution deployed to.
cdk bootstrap aws:///
cdk deploy –all
As part of the CDK deployment, there is an Output value for the React Application URL (FrontendAppStack.ReactAppUrl). You will use this value to interact with the GenAI application. Wait up to 5 mins for the URL to be live.
Post-deployment configuration steps
Now that you’ve deployed the solution, you need to add permissions to allow the Lambda function’s AWS Identity and Access Management (IAM) role and Amazon Bedrock to interact with your Security Lake data.
Grant permission to the Security Lake database
Copy the Lambda’s role ARN from the “BedrockAppStack” CloudFormation stack. The resource in the stack is named “athenaAgentSecurityLakeActionGroupLambdaServiceRole********”.
Go to the Lake Formation console.
Select the amazon_security_lake_glue_db_ database. For example, if your Security Lake is in us-east-1, the value would be amazon_security_lake_glue_db_us_east_1
For Actions, select Grant.
In Grant Data Permissions, select SAML Users and Groups.
Paste the Lambda function IAM role ARN from Step 1.
In Database Permissions, select Describe, and then choose Grant.
Grant permission to Security Lake tables
You must repeat the following steps for each source configured within Security Lake. For example, if you have four sources configured within Security Lake, you must grant permissions for the Lambda function IAM role to each table. If you have multiple sources that are in separate Regions and you don’t have a rollup Region configured in Security Lake, you must repeat the steps for each source in each Region.
The following example grants permissions to the Security Hub table within Security Lake. For more information about granting table permissions, see the AWS Lake Formation user guide.
Copy the Lambda’s role ARN from the “BedrockAppStack” CloudFormation stack. The resource in the stack is named as “athenaAgentSecurityLakeActionGroupLambdaServiceRole********”.
Go to the Lake Formation console.
Select the amazon_security_lake_glue_db_ database. For example, if your Security Lake database is in us-east-1, the value would be amazon_security_lake_glue_db_us_east-1
Choose View Tables.
Select the amazon_security_lake_table__sh_findings_1_0 table. For example, if your Security Lake table is in us-east-1, the value would be amazon_security_lake_table_us_east_1_sh_findings_1_0
Note: Each table must be granted access individually. Selecting All Tables won’t grant the access needed to query Security Lake.
For Actions, select Grant.
In Grant Data Permissions, select SAML Users and Groups.
Paste the Lambda function IAM role ARN from Step 1.
In Table Permissions, select Describe, and then Grant.
Sync data sources
After you deploy the infrastructure, you need to sync the data sources in the Amazon Bedrock knowledge bases so that the data in Amazon S3 can be vectorized and made available in Amazon OpenSearch Serverless, which is the service used as a vector source by the knowledge bases in this solution.
In the Amazon Bedrock console, select Knowledge base and find the two Amazon Bedrock knowledge bases deployed in this solution: gen-ai-sec-lake-table-schema and gen-ai-sec-lake-runbooks. Navigate to each knowledge base and its data source. Then choose Sync for each data source.
Get the CloudFront distribution URL
As part of the sample solution, the chatbot uses an externally available CloudFront distribution URL. It’s recommended that you add appropriate security controls that align to your organization’s security requirements to the sample solution. For example, you might want to add authentication to CloudFront using Amazon Cognito and Lambda@Edge to help prevent unauthorized users from accessing this chatbot. You can also configure secure access and restrict access to the content.
Navigate to CloudFormation in the console.
In the Stacks section, select the FrontendAppStack.
Select the Outputs tab.
Copy the value ReactAppUrl.
Investigate with your security chatbot
Now that you’ve deployed the sample solution and configured the appropriate permissions, you’re ready to use natural language input to generate and invoke SQL queries and to recommend internal incident response playbooks.
Generate and invoke SQL queries
Although most security professionals already know how to create and invoke SQL queries, time is extremely important during a possible security event. Adding natural-language-to-SQL capability to the security agent can help reduce your mean time to respond, which can reduce the overall impact of a security event. Furthermore, you can use these same techniques for threat hunting in your AWS environment.
Question 1: Which AWS accounts have the most security findings for EC2 instances in the last 7 days?
Answer 1: The query results show the top two AWS accounts with the most security findings related to EC2 instances in the last 7 days. The account with ID XXXXXX10 had the highest number of findings at 252, followed by account XXXXXX28 with 197 findings.
The query covered the key requirements, so I provided the final answer summarizing the top accounts and their finding counts.
The question and response are shown in Figure 2.
Figure 2: Response for most EC2 security findings
The more context you provide to the chatbot, the better the query that will be generated. Providing a time window also gives a smaller data set to review and give quicker results.
Question 2: In those AWS accounts, what were the top EC2 security finding types?
Answer 2: Based on the query results, the top EC2 security finding types in the AWS accounts with the most EC2 instance findings in the last 7 days were:
For account XXXXXX10:
“Compliance Finding: Update” with 252 findings
For account XXXXXX28:
“Compliance Finding Update” with 166 findings
“Compliance Finding Create” with 24 findings
“Vulnerability Finding: Update” with 2 findings
“Vulnerability Finding: Create” with 2 findings.
The question and response are shown in Figure 3.
Figure 3: Response for top EC2 security finding types
The results show that the issues are primarily around Security Hub controls mapped to the type_name OCSF column. If you want to look at a different column, you can provide additional instructions or update the question.
Question 3: Which EC2 instances had vulnerability security findings?
Answer 3: Based on the query results, the following EC2 instances had vulnerability security findings in the AWS account with the most EC2 instance findings in the last 7 days:
In account XXXXXX28:
arn:aws:ec2:us-east-1: XXXXXX28:instance/
arn:aws:ec2:us-east-1: XXXXXX28:instance/
There were no vulnerability findings for EC2 instances in account XXXXXX10 during this time period.
The question and response are shown in Figure 4.
Figure 4: Response for EC2 instances with vulnerability security findings
In this question, the search is narrowed down to two Amazon Elastic Compute Cloud (Amazon EC2) instances within a specific AWS account to take a deeper look into.
Recommend incident response playbooks
As part of this sample solution, we used the AWS Incident Response Playbook Samples GitHub repository and uploaded them to an S3 bucket. Alternatively, you can create or reference your own playbooks to investigate and respond to various security events to refer to. After each question, the chatbot provides an answer along with an Amazon S3 URL to the playbook. The security analyst must have the appropriate permissions to download the playbook from Amazon S3.
Question 1: Do I have any playbooks that would help investigate a compromised EC2 instance for crypto mining or malware?
Answer 1: Yes, the search results include a relevant playbook for investigating a potentially compromised EC2 instance that could be used for crypto mining, malware, or ransomware. The key steps outlined in the playbook are:
Acquire, preserve, and document evidence – Identify indicators of compromise, determine attack vector, document impacted applications/users
Contain the incident – Isolate the compromised instance if possible without service disruption, remove from auto-scaling group if applicable
Eradicate the incident – Follow the steps to remove the malware/crypto miner, restore from known good backups/AMIs
Recovery – Spin up new instances from trusted AMIs, restore the data, and monitor for persistence of the threat
Lessons learned – Analyze the incident, identify root causes, and implement preventative measures
The playbook provides detailed guidance on each of these phases in the context of an EC2 ransomware incident, but the overall process can be adapted for investigating crypto mining, malware, or other threats on EC2 as well.
The question and response are shown in Figure 5.
Figure 5: Response for EC2 IR playbooks
The previous threat-hunting exercise identified two EC2 instances that had vulnerabilities present. After further investigation, if a security analyst believes the EC2 instance is compromised, they can ask for an IR playbook to respond to the security event. Once they determine which playbook makes the most sense, they can either click on the S3 URL or look at other playbooks to use.
Question 2: Do I have any playbooks that would help respond to ransomware in my S3 bucket?
Answer 2: Yes, the search results include a playbook that can help respond to a ransomware incident involving an S3 bucket. The “Incident Response Playbook Template for Unintended Access to an Amazon S3 Bucket” outlines steps for:
Gathering evidence of the unintended access
Containing the incident by restricting access to the affected bucket(s)
Eradicating the issue by removing any malicious data/objects and restoring from backup
Recovering by re-enablement access to the bucket for legitimate users
Conducting post-incident activities like reviewing logs, determining root cause, and implementing preventative measures
While focused on generic unintended access rather than ransomware specifically, many of these steps could be adapted and applied to a ransomware scenario targeting data in S3. The playbook provides a solid framework for incident response on S3.
Additionally, the general “Ransomware Incident Response Playbook” template covers common steps for any ransomware incident, such as:
Acquiring and preserving evidence of the ransomware infection
Containing the incident by isolating affected systems
Identifying and remove the ransomware
Recovering data from backups or known good sources
Conducting post-incident review
While not S3-specific, this playbook provides complementary guidance that could be used in conjunction with the S3 access playbook for an S3 ransomware incident.
The question and response are shown in Figure 6.
Figure 6: Response for S3 ransomware IR playbooks
The response provides a high-level overview of the specific playbook that’s being referenced to provide the analyst with context before diving deeper into any single playbook.
Adding functionality to the security chatbot
This sample solution was developed to show the art of the possible. Each customer uses AWS resources to address their business needs in their own way, and security teams must be appropriately equipped to help secure their respective environments. Here are some possible enhancements that you can incorporate into the sample solution to align to your security use-cases and needs.
Incorporate an Amazon DynamoDB table to use as part of reporting interactions tied to a specific event or finding GUID. By incorporating an audit trail, you can tie actions taken by the agent and associated resources to a security event and validate the outcome of the investigation before taking action.
Tuning the backend chatbot agent to query Amazon Linux Security Center’s Common Vulnerabilities and Exposures (CVE) list or MITRE’s CVE list to see which AWS resources might be in scope and send out consolidated messages to resource owners with recommended actions.
Tuning the backend chatbot agent to take natural language requests and respond with detectors or correlation rules for Amazon OpenSearch or query language for custom detections in your security information and event management (SIEM) tool.
Adding a new data source to Athena, such as AWS Config, to provide the analyst with additional capabilities to query AWS resource configuration across the AWS environment that might have been impacted by a security event. For example, if a security finding shows that an S3 bucket has been made public, querying what and when other configuration changes were made to the S3 bucket.
Incorporating multi-agent-orchestration to scale the use of multiple Amazon Bedrock agents that can be tuned towards niche security use cases by respective teams. The chatbot can speak directly to a classifier or controller, which then addresses the user’s natural language request and orchestrates across one or more agents to generate a response. For example, if a user asks which EC2 instances might have been impacted by a security event and which playbook to use to respond, the classifier agent could direct the initial query to the agent in this sample solution. In the same chat window, the analyst could ask if there are any open CVEs for the EC2 instances in scope to get a list of CVEs to address within the AWS account.
For long running Athena queries, you can incorporate an AWS Step Function to the workflow and incorporate a task token to wait for the Athena results to return.
Clean up
If you deployed the security chatbot sample solution by using the Launch Stack button and the console with the CloudFormation template security_genai_chatbot_cfn, do the following to clean up:
In the CloudFormation console for the account and Region where you deployed the solution, choose the SecurityGenAIChatbot stack.
Choose the option to Delete the stack.
If you deployed the solution by using the AWS CDK, run the command cdk destroy –all.
Conclusion
The sample solution demonstrates how you can use task-oriented Amazon Bedrock agents and natural language input to help accelerate investigation and analysis and increase your overall security posture. We provided an example of a sample solution with a user interface that is powered by an Amazon Bedrock agent, which you can extend to add additional task-oriented agents, each with their own instructions, knowledge bases, and models. By extending the use of AI-powered agents, you can help your security team operate more efficiently across multiple security domains within your AWS environment.
The backend for the chatbot to investigate security events uses Security Lake, which normalizes data into Open Cybersecurity Schema Framework (OCSF); as long as the data schema is normalized, the solution can be applied to other data lakes within your AWS environment.
To learn more, see the other posts in this series:
Part 1: Generate machine learning insights for Amazon Security Lake data using Amazon SageMaker
Part 2: Generate AI powered insights for Amazon Security Lake using Amazon SageMaker Studio and Amazon Bedrock
Use the comments section to provide feedback. If you have questions about this post, start a new thread on the Generative AI on AWS re:Post or contact AWS Support.
Madhunika Reddy Mikkili
Madhunika is a Data and Machine Learning Engineer at AWS. She is passionate about helping customers achieve their goals using data analytics and machine learning.
Jonathan Nguyen
Jonathan is a Principal Security Solution Architect at AWS. He helps large financial services customers develop a comprehensive security strategy and solutions to meet their security and compliance requirements in AWS.
Harsh Asnani
Harsh is a Machine Learning Engineer at AWS specializing in ML theory, MLOPs, and production generative AI frameworks. His background is in applied data science with a focus on operationalizing AI workloads in the cloud at scale.
Michael Massey
Michael is a Cloud Application Architect at AWS, where he specializes in building frontend and backend cloud-centered applications. He designs and implements scalable and highly-available solutions and architectures that help customers achieve their business goals.t


